

2024. 3. 14. 12:52ㆍProgramming Language/C++
문자형(char, wchar_t 등)에 정수값을 넣으면 문자를 표현하는 자료형이기 때문에 정숫값과 그 정수에 대응하는 문자까지 저장한다.
여기서 문자는 아스키(ASCII) 코드값을 뜻한다.
아스키(ASCII) 코드
• 영문 알파벳을 사용하는 대표적인 문자 인코딩이다.
C/C++는 아스키 코드를 이용하여 문자를 인코딩한다.
인코딩(Encoding)
• 입력한 문자를 컴퓨터가 이용 가능한 신호로 만드는 것
쉽게 말해서 우리가 사용하는 문자나 기호를 컴퓨터가 읽을 수 있는 2진수로 변환하는 것이다.
int main()
{
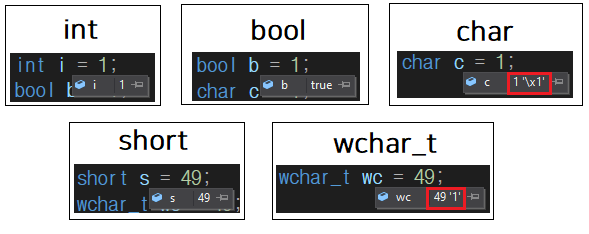
// 크기가 1byte인 자료형
int i = 1; // 1
bool b = 1; // true
char c = 1; // 1 '\x1'
// 크기가 2byte인 자료형
short s = 49; // 49
wchar_t wc = 49; // 49 '1'
return 0;
}
아스키 코드 표(ASCII Code Table)
• 정숫값이 어떤 문자에 해당하는지를 나타낸 표

▷ 예시
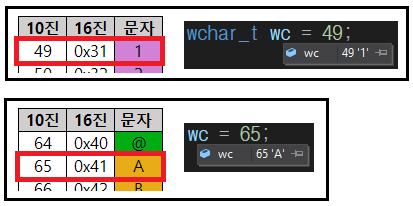
아스키 코드 표에 나와있는 것처럼 숫자 49는 문자 1, 숫자 65는 문자 A가 저장된다.
다중 바이트 인코딩 vs. 와이드 문자 인코딩
1) 다중 바이트 인코딩 (EUC-KR, UTF-8 등)
• 문자열은 다중 바이트 인코딩 형식으로 저장된다.
• 1바이트로 표현할 수 없는 한글 문자를 다루기 위해 2바이트 이상을 사용하는 방식이다.
• 한글 문자는 2바이트 이상으로 저장되고, 음수 바이트 값으로 저장된다.
char cArr[10] = "abc한글";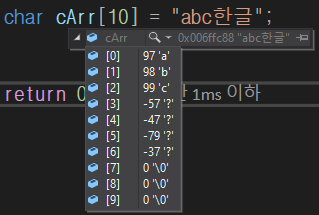
`-57 '?'`, `-47 '?'` = 한
`-79 '?'`, `-37 '?'` = 글
이 음수 값들은 EUC-KR 인코딩에서 멀티 바이트 문자를 저장할 때 표현되는 값이다.
2) 와이드 문자 인코딩
• 문자열은 와이드 문자 형식(UTF-16)으로 저장되며, 모든 문자는 2바이트씩 저장된다.
• 한글 문자는 양수 정수 값으로 저장된다.
wchar_t wChar[10] = L"abc한글";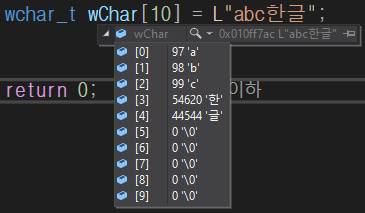
`54620 '한'` = 한
`44544 '글'` = 글
0 vs. SP(space, 공백) vs. '0'
• 0에 대응되는 문자 = NUL (아무것도 없는 상태)
문자열 맨 뒤에 숫자 0은 문자의 끝을 의미한다.
즉, 마침표 역할을 한다고 생각하면 된다.

NUL은 NULL의 준말이다.
• SP(Space, 공백)에 대응되는 숫자 = 32

공백(SP)은 <Spacebar>를 누르면 생기는 공백을 말한다.
• '0'에 대응되는 숫자 = 48

▷ `"4 59"`

| 52 | 32 | 53 | 57 | 0 |
4와 5 사이의 공백 자리에 숫자 32가 저장된다.
아스키 코드 표에서 숫자가 0~127까지 있는 이유
1byte는 0~255까지 표현할 수 있지만 메모리를 온전히 다 사용할 수는 없다.
오류 검출을 위한 패리티 비트가 1bit 존재하므로 실제로는 7bit만 사용할 수 있고, 표현할 수 있는 값은 0~127이다.
• 패리티 비트(parity bit)
정보 전송 과정에서 오류를 검출하기 위해 추가되며, 1bit 오류를 찾아낼 수 있는 비트이다.
오류 체크만 하고 고쳐주지는 않는다.
고쳐주는 코드는 해밍코드이다.
• 해밍 코드(hamming code)
패리티 비트를 이용하여 오류를 검출하고 교정한다.

'Programming Language > C++' 카테고리의 다른 글
| [C++] 가변 배열 (0) | 2024.03.17 |
|---|---|
| [C++] 동적 할당, malloc()/free() vs. new/delete (0) | 2024.03.15 |
| [C++] void 포인터(void*) (0) | 2024.03.14 |
| [C++] const와 포인터 (0) | 2024.03.14 |
| [C++] 문제 풀어보기[포인터, 변수] (풀이 및 설명 포함) (0) | 2024.03.13 |